
By António Pedro Costa, University of Aveiro – Portugal
Content Analysis is a technique of data analysis, collected in various sources, but expressed, preferably, in texts or images. The nature of these documents can be very varied, such as archival material, literary texts, reports, news, evaluative comments of a given situation, diaries and autobiographies, transcripts of interviews, requested texts on a specific topic, field notes, etc. The same can be said about the nature of the images: photographs, films, illustrations from books, etc. Content Analysis is a natural, spontaneous process that we all use when we underline ideas in a text and advance to its organization and synthesis to better understand and retain them (Amado, Costa, & Crusoe, 2014).
Currently, the use of software to support this technique allows for faster, more rigorous and highly complex processes that can be safely performed. In this context, Costa & Amado wrote two books: 1) Content Analysis in seven steps with webQDA (2017b) and 2) Content Analysis with software (2017a), in which they present a proposal to apply this technique, as follows:
- Definition of the problem, work objectives and theoretical basis;
- Organization of the Data Corpus;
- Reading the Data;
- Categorization and Codification;
- Formulation of Questions;
- Matrices Analysis;
- Presentation of Results.
As an example of point 3, Reading the Data, the authors say that the initial reading or the first reading of the data acts as a pre-analysis, allowing the identification of some key ideas. However, webQDA has features that can help with the first definition of categories / sub-categories. For example, independently of and beyond the path that is determined for the definition of the categories, emerging from the data (empirical, inferential categories) or through the theoretical reference (theoretical categories), the researcher can search for “Frequent words” and, from there, develop categories of analysis (see figures).
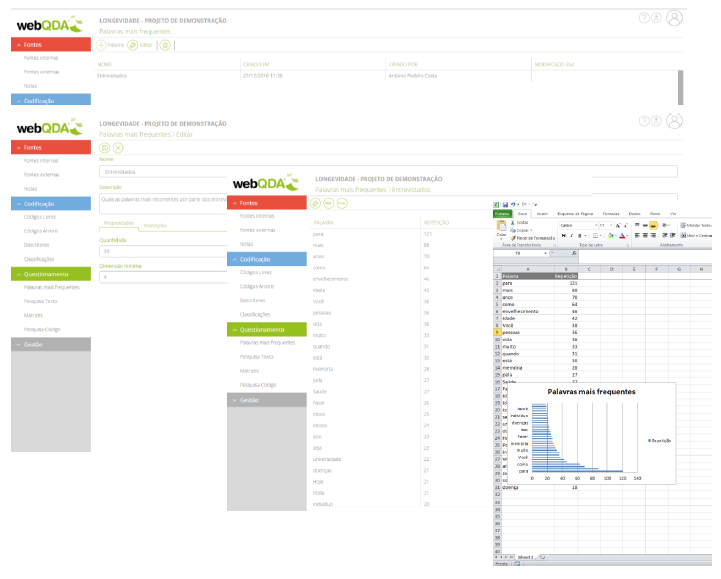
Figure 1 – Frequent Word Search
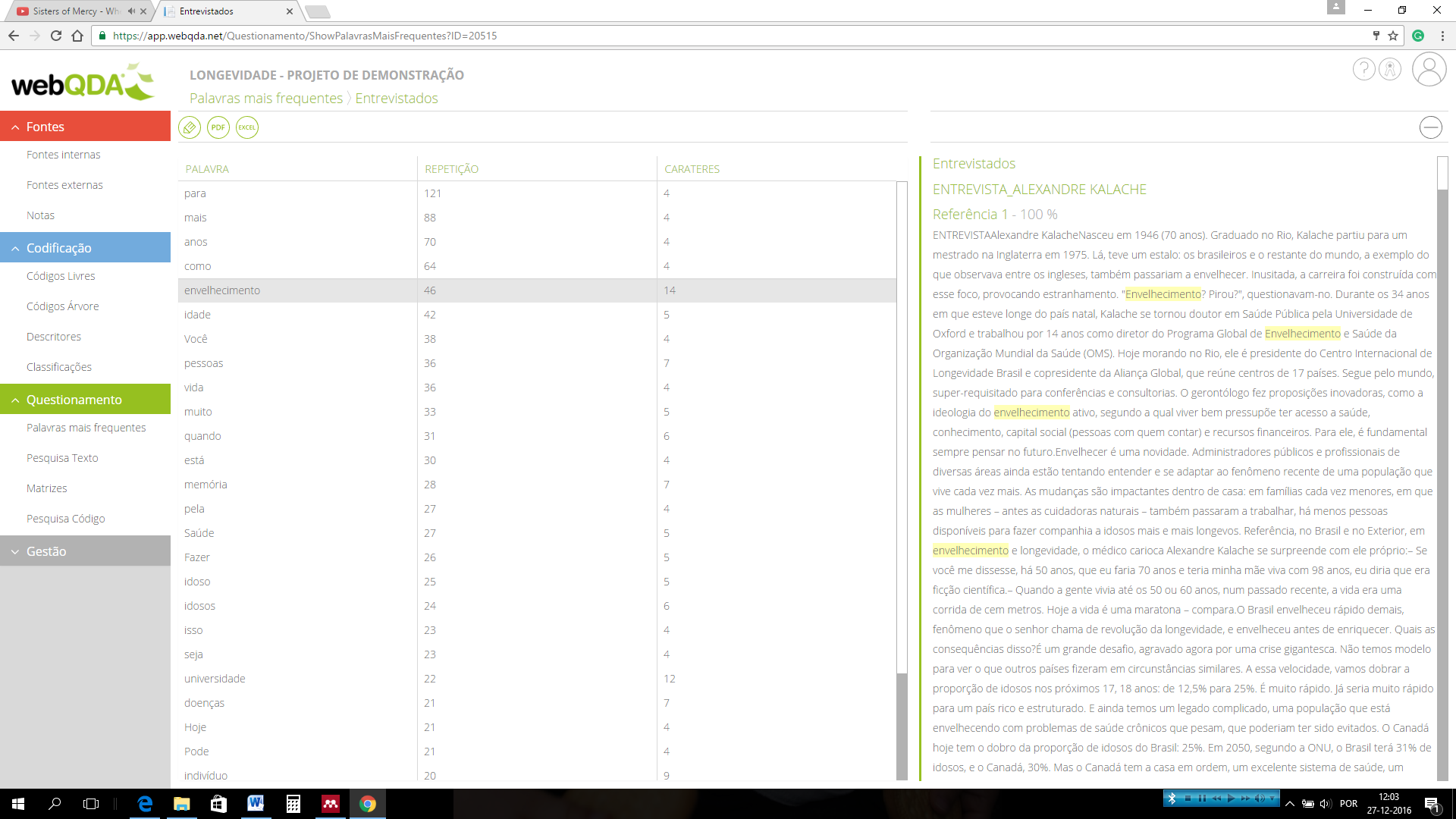
Figure 2 – Search result of the word “aging”
It is up to the researcher to decide how and which data to encode and ensure that the use of the software fits into its theoretical framework, context and research questions.
References
Amado, J., Costa, A. P., & Crusoé, N. (2014). A Técnica de Análise de Conteúdo. In J. Amado (Ed.), Manual de Investigação Qualitativa em Educação (2a ed, pp. 301–350). Coimbra: Imprensa da Universidade de Coimbra.
Costa, A. P., & Amado, J. (2017a). Análise de Conteúdo com software. (A. P. Costa, F. N. de Souza, & D. N. de Souza, Eds.) (no prelo). Oliveira de Azeméis – Aveiro – PORTUGAL: Ludomedia.
Costa, A. P., & Amado, J. (2017b). Análise de Conteúdo em sete passos com o webQDA (e-book). (A. P. Costa, F. N. de Souza, & D. N. de Souza, Eds.) (1st ed.). Oliveira de Azeméis – Aveiro – PORTUGAL: Ludomedia.






Leave a comment