 for Qualitative Data Analysis with Integration of webQDA Software")
Seven Essential Steps (Cross-cutting Subtasks) for Qualitative Data Analysis with Integration of webQDA® Software
Francislê Neri de Souza
Dayse Neri de Souza
The seven essential steps or subtasks that we will describe below are transversal or generic to qualitative data analysis techniques. The technique’s focus on the analysis rests on specific choices according to each objective and research questions. However, we believe that these steps can be used generically, using most analysis techniques: content analysis, discourse analysis, analysis framework, grounded theory, narrative analysis. These essential steps are not substitutes for the careful study of these techniques and their coherence for data analysis in specific research.
The objective of describing these steps is to give the beginner students in qualitative research a notion of the effort required to rigorously and systematically carry out the data analysis. We believe that many of these students underestimate the task of data analysis and its subtasks. On the one hand, making the analysis superficial, light, and without scientific rigour, and on the other hand, mixing stages, intertwining processes in a labyrinth of complexity without resolution.
These steps will be described in a simple and summarized form to be used in a detailed research schedule based on the research internal coherence matrices. Further details on the internal coherence matrices 1 can be obtained in the work of Neri de Souza, Neri de Souza, & Costa (2014).
Subtask 1 (ST1) – Survey and organization of data in webQDA (interviews, online interactions, classroom observations, open-ended questionnaire questions, videos, online forums, Youtube comments, video conference recordings and remote classes, etc.). In this step, we can have, for example, the floating or active reading as indicated by Bardin (2004) and Amado (2017) in the books “Content analysis” and “Manual of qualitative education research”, respectively. However, whichever technique is chosen, the researcher will always have to gather all the data and organize it in the webQDA Sources System. Many beginning students are unaware of all the available data that they have collected in their research interventions.
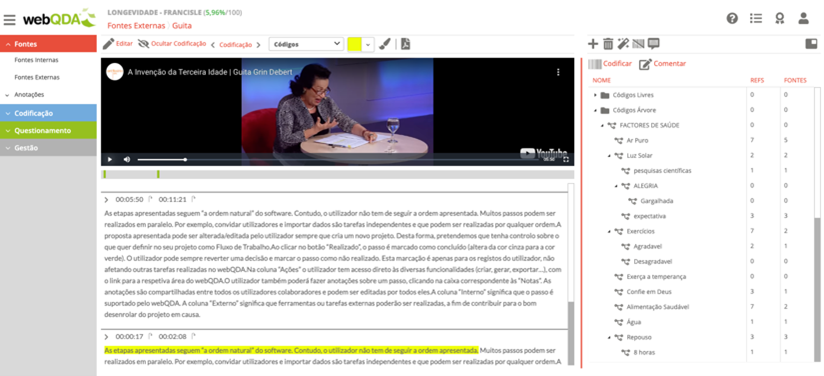
Subtask 1 (ST1) – Survey and organization of data in webQDA
Subtask 2 (ST2) – Creation of an analysis system coposed of free codes and tree codes. Each code title or name (category of analysis) must be short, accompanied by a more detailed description in webQDA. We advise that to give these titles a maximum of 3 words, the researcher must prioritize the subject’s essence and exercise a great power of synthesis, but it must be more explanatory in the description.
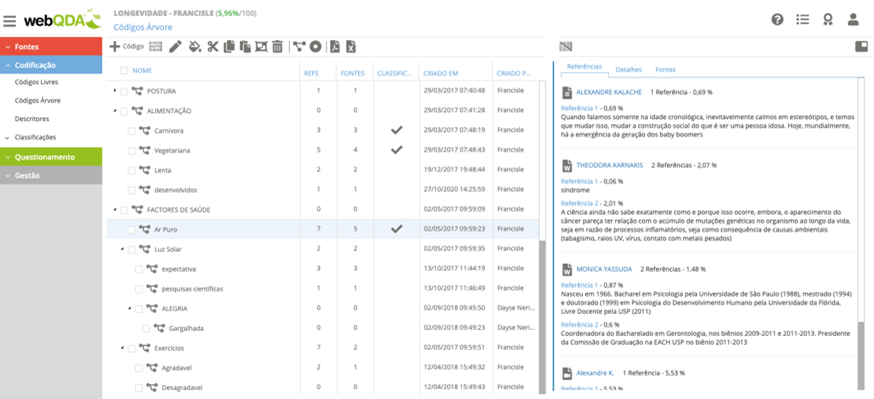
Subtask 2 (ST2) – Creation of an analysis system creating free codes and tree codes
Subtask 3 (ST3) – Validate with the specialist (advisor) the first version of the analysis system: Dimensions, categories and subcategories of analysis (tree codes). Cross these categories emerging from the fluctuating reading of the data with the objectives and research questions. Create the internal coherence matrix 2, as described by Neri de Souza, Neri de Souza, & Costa (2014).
Subtask 4 (ST4) – Encode the data based on this first assessment or validation cycle. Select the text and code according to the title and description that were created in ST2. There are many coding techniques, but it is usually performed by the researcher who collected the data. WebQDA provides conditions for collaborative coding between several researchers (human coders) in the same project. At this stage (ST4), we believe that artificial intelligence can assist (soon in a more accessible way) the encoding of large volumes of data, which will then be validated in stage ST5. We believe that several external human coders can also be used in this phase, but they must be “programmed” and artificial intelligence to code according to the theoretical assumptions, objectives, and research questions thought out in the previous subtasks. Again, it will always be necessary to validate this coding process, whether done by a single researcher who collected the data, external human coders, the research group, or artificial intelligence.
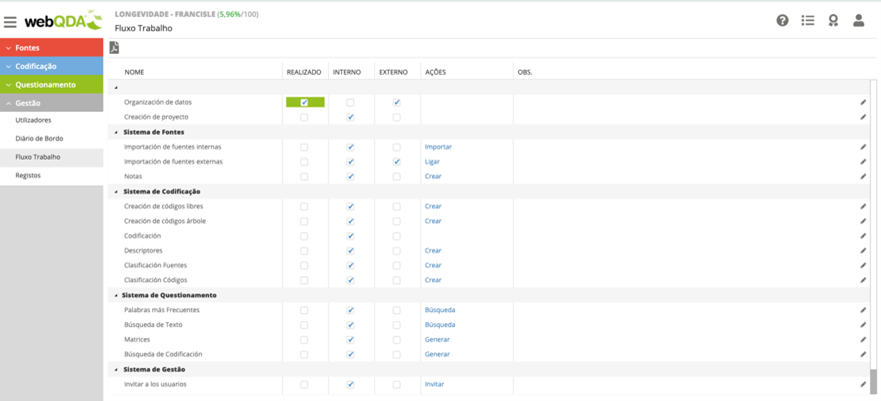
Subtask 4 (ST4) – Encode the data based on this first assessment or validation cycles
Subtask 5 (ST5) – Validate with the advisor and other specialists the text units (“references” in the webQDA lingo) coded in the dimensions, categories and subcategories. There are several validation processes, but we can define at least four subtasks for this validation process after the initial coding:
- choose a set of categories and subcategories to be validated (theoretical sampling);
- select a set of references (text units) to compose a table in Word indicating category, definition and list of references;
- forwarding a Word table to a panel of judges to analyze the coding of this theoretical sampling of codes and references;
- compare the codings of this theoretical sampling of the panel of judges with the researcher’s initial coding.
There are other validation processes, also helpful. For example, the project on webQDA can be shared in visualization so that the panel of judges can declare agreement or disagreement with the specific codifications pointed out by the researcher. However, this would be another set of validation subtasks.
Subtask 6 (ST6) – Ask questions about the coded category system (tree codes). For example, asking questions about the relationship between descriptive codes (e.g., age, sex, profession etc.) and interpretive codes (free codes and tree codes in webQDA). Elements for building answers to these and many other questions can be obtained through various webQDA tools, such as code search, text search, reference and code counting system in “Tree Codes” and quadrangular/triangular matrices. We recommend that this questioning be systematized through the third matrix of internal coherence (Neri de Souza, Neri de Souza, & Costa, 2014).
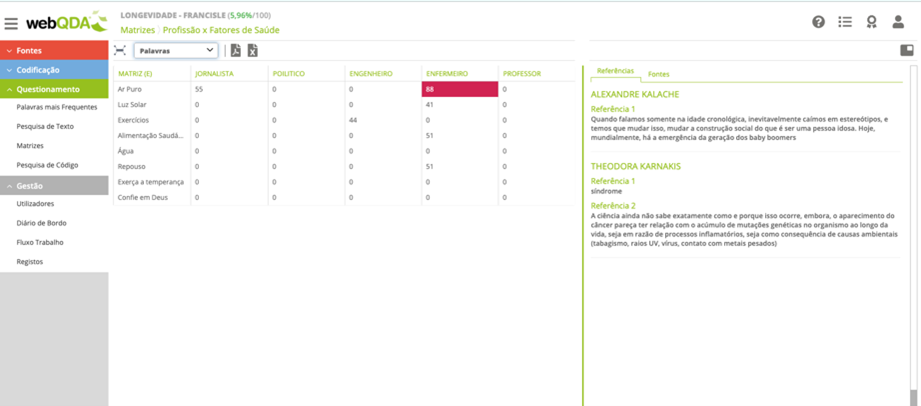
Subtask 6 (ST6) – Ask questions about the coded category system (tree codes)
Subtask 7 (ST7) – Consolidate all notes, observations, questions and validations in a final descriptive, interpretative and triangulation text with the literature (discussion). For the writing of this final analysis text, it is necessary to have webQDA open to obtain information, matrices and references as examples in the construction of inferences and discussion of data. For the construction of this text, we suggest starting with an overview of the analysis system, presenting the reader with dimensions, categories and subcategories, along with a detailed and accurate view of the data encoded through matrices and frequencies and examples of each code’s references.
References (APA 7th)
Amado, J. (2017). Manual de investigação qualitativa em educação. Coimbra: Imprensa da Universidade de Coimbra.
Bardin, L. (2004). Análise de Conteúdo (3a). Lisboa: Edições 70.
Neri de Souza, F., Neri de Souza, D., & Costa, A. P. (2014). Importância do Questionamento em Todo o Processo de Investigação Qualitativa. In A. P. Costa, F. Neri de Souza, & D. Neri de Souza (Eds.), Qualitativa: Inovação, Dilemas e Desafios (1a, pp. 125–145). Aveiro – Portugal: Ludomedia.





A clear and practical guide! These seven essential steps, enhanced by webQDA integration, streamline qualitative data analysis for researchers at all levels. Also, check out our stylish Leather Vest!
This is a very well-structured overview of qualitative data analysis, especially the way cross-cutting subtasks are connected with WebQDA tools. I like that the article focuses not only on software features, but also on the analytical thinking behind the process.
In practice, these kinds of frameworks are becoming increasingly relevant beyond academia, including digital projects and platform analysis in cities like
Barcelona,
where data-driven decision making plays a growing role. Clear methodologies like the one described here help ensure that qualitative insights are not lost during complex analysis workflows.